
业务挑战
该金融集团主要提供保险、银行、资管等综合金融服务。公司持续推动智能化、数字化经营,坚持以客户为中心,从客户需求出发,借助科技创新成果为客户提供高效的一站式综合金融解决方案。
作为一家全国性的大型金融机构,该集团的数据安全需求极为重要且复杂,需要严格遵守《数据安全法》、《个人信息保护法》等法律法规,确保数据处理活动的合法性、正当性,同时,金融监管机构对金融机构的数据安全有严格的监管要求,该集团需要确保自身数据安全管理体系符合监管标准,并接受监管机构的检查和评估。
实现难点
- 多种数据库类型,都需要实现加密和分片,由于数据库之间存在差异,重复实现数据加密和分片的难度大;
- 缺乏统一的管控平台,无法进行加密和分片的统一管理;
- 由于业务 SQL 复杂多变,实现 SQL 透明加密和透明化分片的技术难度大,难以保证兼容度和性能;
方案亮点
- 使用 DBPlusEngine 可以适配多种不同的数据库类型,统一对加密和分片需求进行管理;
- 通过 Console 可视化页面,可以高效地完成加密改造和分片改造;
- DBPlusEngine 基于 SQL 语义,内部自动实现加密和分片的执行,能够保证 SQL 兼容度和性能,并且业务层无需改造;
解决方案
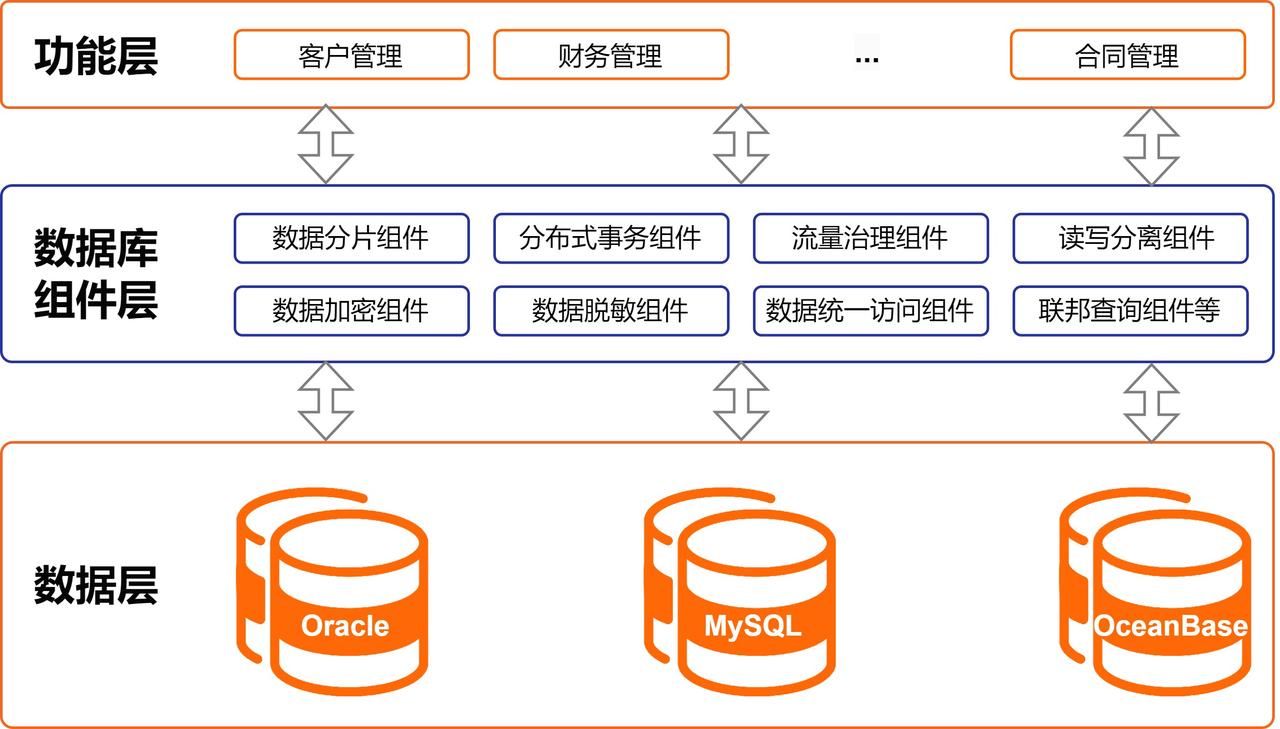
该金融集团从 2019 年开始使用开源软件 ShardingSphere ,以 ShardingSphere 为核心,打造全集团统一的数据层中间件,对 MySQL、Oracle、OceanBase 等多种数据库类型进行统一管理,在集团各个业务系统全面推广,构建统一的数据管理体系,实现应用与数据库解耦,开发统一的数据访问接口便于数据整合,打造数据安全体系,简化开发、提升数据管理的灵活性,增强扩展性,降低业务系统开发及运维成本。
数据分片
数据分片(Data Sharding)是将单表中的数据分散地存放至多个数据库或表中,每个分片包含一部分数据。数据分片可以提高数据处理的性能、可扩展性和并行处理能力,从而满足现代数据处理需求。
ShardingSphere 支持多种分片策略,包括垂直分片和水平分片。垂直分片按照业务逻辑将表进行归类,分布到不同的数据库中;水平分片则通过某个字段(或某几个字段)根据某种规则将数据分散至多个库或表中。
ShardingSphere 数据分片的应用场景
- 高并发访问:在处理大量用户请求的场景中,ShardingSphere 数据分片可以显著提高系统的并发处理能力,确保服务的稳定性和响应速度。
- 大数据量处理:在海量数据处理处理场景中,ShardingSphere 数据分片可以将数据分散到多个节点上,提高数据的并行处理能力,降低处理时间。
- 业务扩展:随着业务的发展,数据量不断增加。ShardingSphere 数据分片可以方便地扩展存储和处理能力,满足业务增长的需求。
分布式事务
- 分布式事务可以确保在多个数据库上执行的多个操作要么全部成功,要么全部失败,从而避免数据不一致的问题。
ShardingSphere 对外提供 begin/commit/rollback 传统事务接口,通过 LOCAL,XA,BASE 三种模式提供了分布式事务的能力,
LOCAL 事务:LOCAL 事务基于 ShardingSphere 代理的数据库 begin/commit/rolllback 的接口实现, 对于一条逻辑 SQL,ShardingSphere 通过 begin 指令在每个被代理的数据库开启事务,并执行实际 SQL,并执行 commit/rollback。 由于每个数据节点各自管理自己的事务,它们之间没有协调以及通信的能力,也并不互相知晓其他数据节点事务的成功与否。 在性能方面无任何损耗,但在强一致性以及最终一致性方面不能够保证。
XA 事务:XA 事务采用的是 X/OPEN 组织所定义的 DTP 模型 所抽象的 AP(应用程序), TM(事务管理器)和 RM(资源管理器) 概念来保证分布式事务的强一致性。 其中 TM 与 RM 间采用 XA 的协议进行双向通信,通过两阶段提交实现。 与传统的本地事务相比,XA 事务增加了准备阶段,数据库除了被动接受提交指令外,还可以反向通知调用方事务是否可以被提交。 TM 可以收集所有分支事务的准备结果,并于最后进行原子提交,以保证事务的强一致性。
BASE 事务:基于 BASE 事务要素的事务称为柔性事务。 BASE 是基本可用、柔性状态和最终一致性这三个要素的缩写。
- 基本可用(Basically Available)保证分布式事务参与方不一定同时在线;
- 柔性状态(Soft state)则允许系统状态更新有一定的延时,这个延时对客户来说不一定能够察觉;
- 最终一致性(Eventually consistent)通常是通过消息传递的方式保证系统的最终一致性。
读写分离
数据库读写分离是一种数据库架构设计策略,在这种架构中,主数据库(Master)负责处理所有的写操作(如INSERT、UPDATE、DELETE),而一个或多个从数据库(Slave)负责处理读操作(如SELECT)。通过将数据库的读操作和写操作分配到不同的数据库服务器上,可以减轻主数据库的负载,提高整个数据库系统的并发处理能力及扩展性。
在 ShardingSphere 中,用户可以根据业务需求灵活的进行读写分离配置,ShardingSphere 支持读写分离的独立使用,也支持读写分离与数据分片等功能配合使用,实现更复杂的数据库架构。
ShardingSphere 读写分离的应用场景:
- 高并发访问:在需要处理大量用户请求的场景中,ShardingSphere 读写分离可以显著提高系统的并发处理能力,确保服务的稳定性和响应速度。
- 读写分离需求:对于业务系统中读操作远多于写操作的情况,使用ShardingSphere 读写分离可以分散数据库的负载,提高系统的性能。
数据库统一访问
多样化的数据库的存在,使访问数据库的 SQL 方言难于标准化,工程师需要针对不同种类的数据库使用不同的方言,缺乏统一化的查询平台。
ShardingSphere 数据库网关使用 SQL 方言技术,可以屏蔽业务应用与底层多元化数据库之间连接,同时为不同的业务场景提供统一的访问协议和语法体系,帮助企业快速打造统一的数据访问平台。
流量治理
实现从数据库到计算节点打通的一体化管理能力,在故障中为组件提供细粒度的控制能力。
计算节点过载保护:当 ShardingSphere 集群内某个计算节点超过负载后,通过熔断功能,阻断应用到该计算节点的流量,保证整个集群继续提供稳定服务。
存储节点限流:在读写分离的场景下,当 ShardingSphere 集群内某个负责读流量的存储节点承接超负荷的请求时,通过限流功能,阻断集群内计算节点到该存储节点的流量,以保证存储节点集群正常响应。
数据迁移
ShardingSphere 数据迁移插件实现了同构数据库由单体到分布式的拆分迁移,该迁移操作可在线完成,同时支持源端目标段的数据比对。ShardingSphere 数据迁移可减少数据迁移时的业务影响,提供一站式的通用数据迁移解决方案。
数据加密
数据加密是指通过特定的算法将原始数据(明文)转换为密文的过程,SphereEx 数据安全平台对数据库中的敏感数据进行加密处理,以防止数据泄露和非法访问。
根据业界对加密的需求及业务改造痛点,ShardingSphere 提供了一套完整、安全、透明化、低改造成本的数据加密整合解决方案。使用 ShardingSphere 的加密功能,可以快速完成数据的合规化加密,客户无需自行开发复杂的加密系统,同时 ShardingSphere 加密功能的灵活性,也能够帮助客户避免加密场景变更带来的复杂重构和修改风险。
数据脱敏
数据脱敏是对敏感数据进行脱敏处理,使其在不改变原始数据含义的前提下,降低或消除数据中的敏感信息,从而保护个人隐私和商业机密。
数据脱敏的目的:
- 保护隐私:保护个人隐私信息,如姓名、身份证号、电话号码等。
- 数据安全:防止企业敏感数据泄露。
- 合规性:满足法律法规对数据保护的要求。
根据业界对脱敏的需求及业务改造痛点,ShardingSphere 提供了一套完整、安全、透明化、低改造成本的数据脱敏整合解决方案。不论是快速上线新业务,还是已经上线的成熟业务,都可以接入 ShardingSphere 脱敏功能,快速地完成脱敏规则的配置。客户无需开发耦合于业务系统的脱敏功能,不需要改动任何业务逻辑和 SQL 就能够透明化地使用脱敏功能。
影子库
在基于微服务的分布式应用架构下,业务需要多个服务是通过一系列的服务、中间件的调用来完成,所以单个服务的压力测试已无法代表真实场景。
在测试环境中,如果重新搭建一整套与生产环境类似的压测环境,成本过高,并且往往无法模拟线上环境的复杂度以及流量。 为了提升系统压力测试的准确性,降低测试成本。通常选择在生产环境进行压力测试。测试中风险也会大大提高。
通过 ShardingSphere 影子库功能,结合影子算法灵活的配置。可以解决数据污染,数据库性能等问题,满足复杂业务场景的在线压力测试需求。
联邦查询
ShardingSphere 提供联邦查询功能,当需要进行跨数据库关联查询、子查询、聚合查询时,不需要改动 SQL,通过配置开启联邦查询即可完成分布式查询语句的执行。ShardingSphere 将业务端原有的查询,转换为分布式查询并在分布式查询场景下进行相应的 SQL 优化,能够在跨数据库实例的情况下完成:关联查询、子查询、分页、排序、聚合查询,研发人员不必再关心 SQL 的使用范围,能够专注于业务功能开发,减少业务层面的功能限制。
系统监控
ShardingSphere 通过 Agent 模块为应用提供可观察性的能力,对系统可观察性数据进行采集、存储和分析,进行系统的性能监控与诊断,主要功能包括性能指标监控、调用链分析,应用拓扑图等。具体包括:
系统信息
采集系统静态信息(如应用版本)和动态信息(如线程数、SQL 处理信息)等指标,管理员能够通过可视化的方式监控系统实时状态。
应用性能监控
可以了解 SQL 执行过程中每一步的耗时情况,轻松定位性能风险,从而能够有针对性的制定 SQL 优化方案。
应用链路追踪
通过对 SQL 执行过程的完整链路追踪,用户可以得到 “SQL 从哪里来,发到哪里去” 这样的完整信息,还能够通过生成的拓扑图来直观的观察 SQL 路由情况,运筹帷幄,同时获得快速定位问题根源的能力。
客户收益
- 构建统一的数据管理体系:打造全集团统一的数据层中间件,构建统一的数据管理体系,对各类数据库进行统一管理。
- 应用与数据库解耦:开发统一的数据访问接口便于数据整合,简化开发,提升数据管理的灵活性,增强扩展性,降低开发及运维成本。
- 建设数据安全治理体系:基于 ShardingSphere 数据安全组件,对业务数据进行统一的数据安全管理,建设完善的数据安全治理体系。
- 打造数据安全管理规范:实现数据分类分级,制定并执行严格的数据安全管理制度,明确数据安全责任边界,规范数据处理流程。
